高级设置详解
以下内容将为您介绍软件高级设置部分
任务基本设置
工作状态恢复
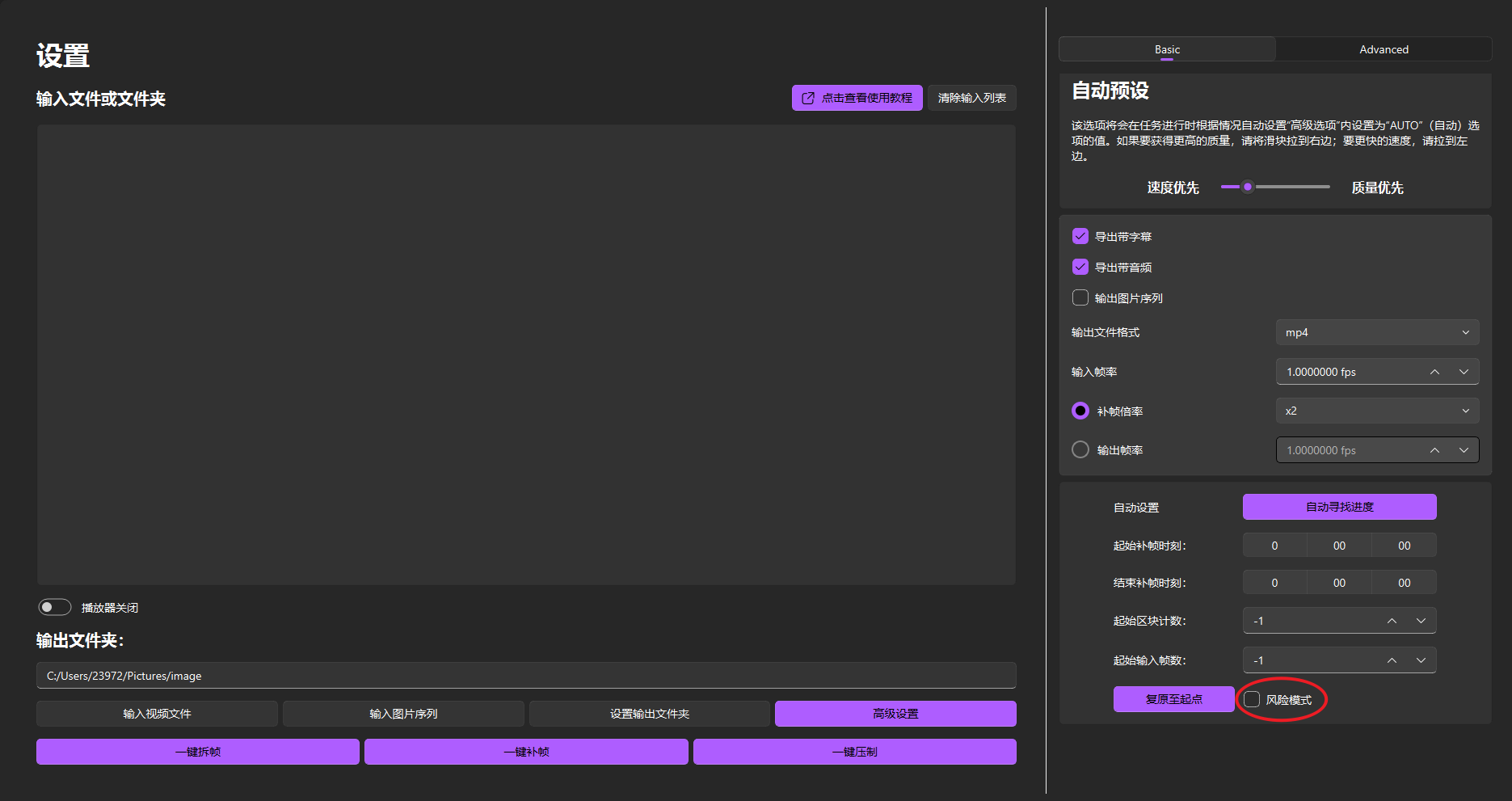
自动寻找进度
提示
- 当遇到任务中途断电或者其他以外情况终止任务导致程序退出的情况,可以通过点击自动寻找进度来恢复上次的区块位置。
- 也可以直接将项目文件夹拖入软件中,软件将自动寻找该项目文件夹对应的进度。
点击此按钮前请您先点击要恢复进度的任务条目。随后点击“一键补帧”,软件将弹窗向您确认补帧起始位置。
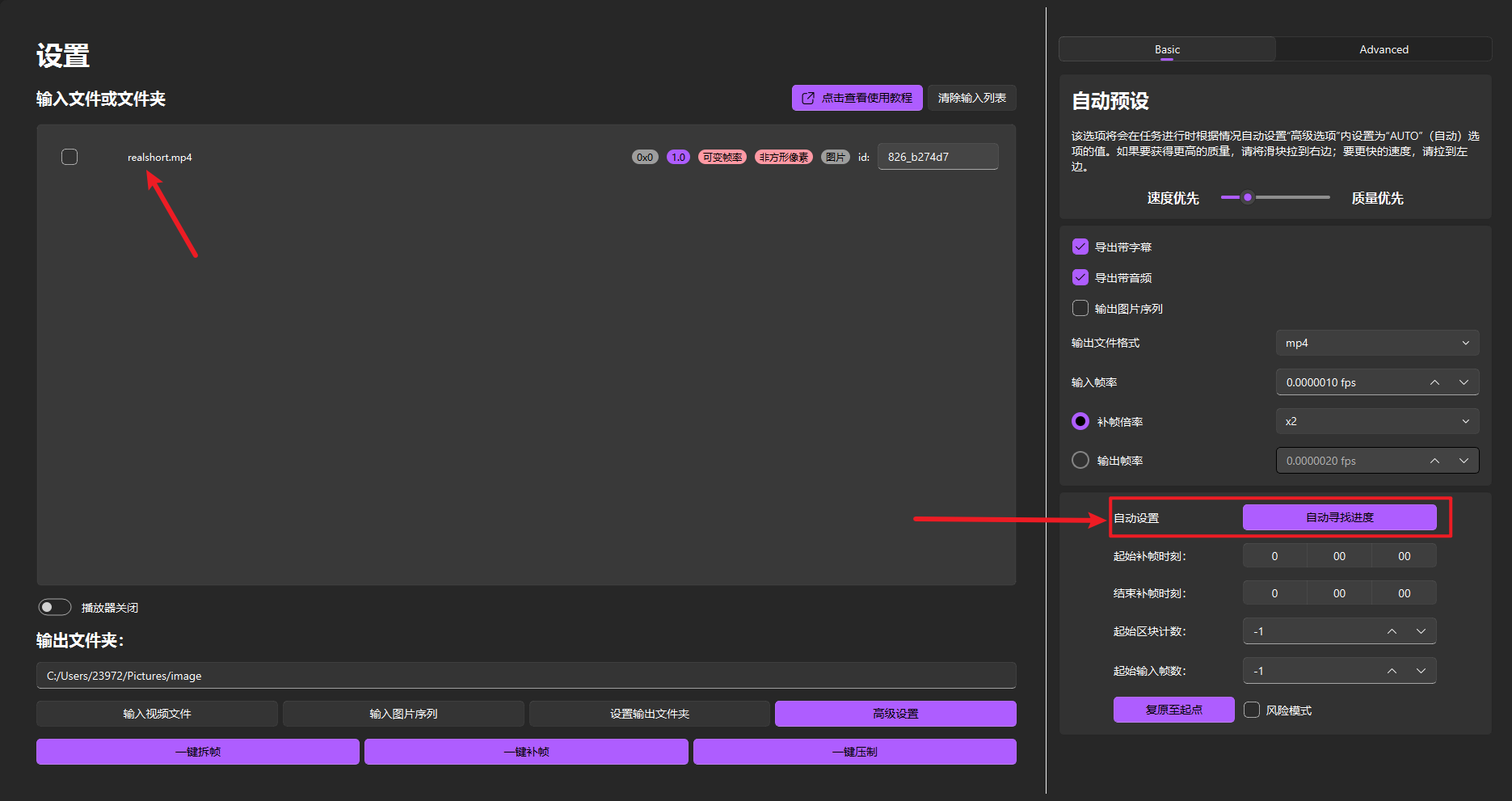
起始补帧时刻和结束补帧时刻
可以选择需要补帧的时间段
输入格式: 小时:分钟:秒
注意
指定起始补帧时刻和结束补帧时刻后,手动终止或断电后可能会导致进度恢复失败
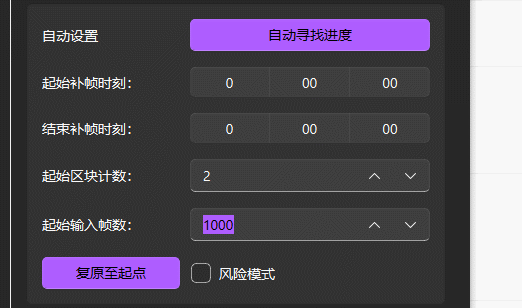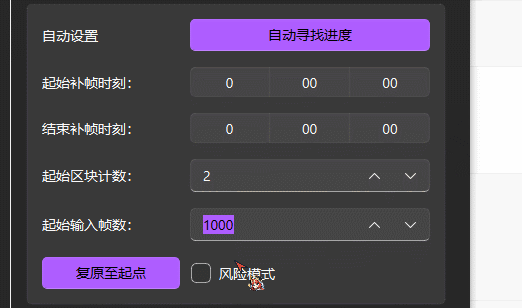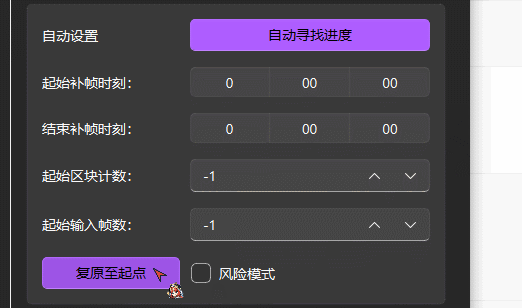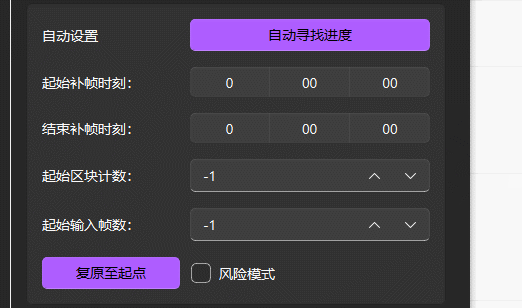
起始区块计数和起始输入帧数
自动寻找进度失败或需手动指定补帧起始位置时用,可用于手动恢复补帧进度
- 起始区块计数 = 输出文件夹中导出的最后一个chunk数 + 1(例如图中的chunk-001,应将起始区块计数为1+1=2)
- 起始输入帧数 = 输出质量设置(渲染设置)中
单一输出区块大小 * (起始区块计数 - 1)
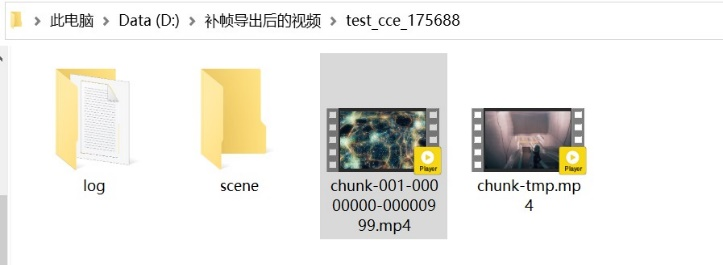
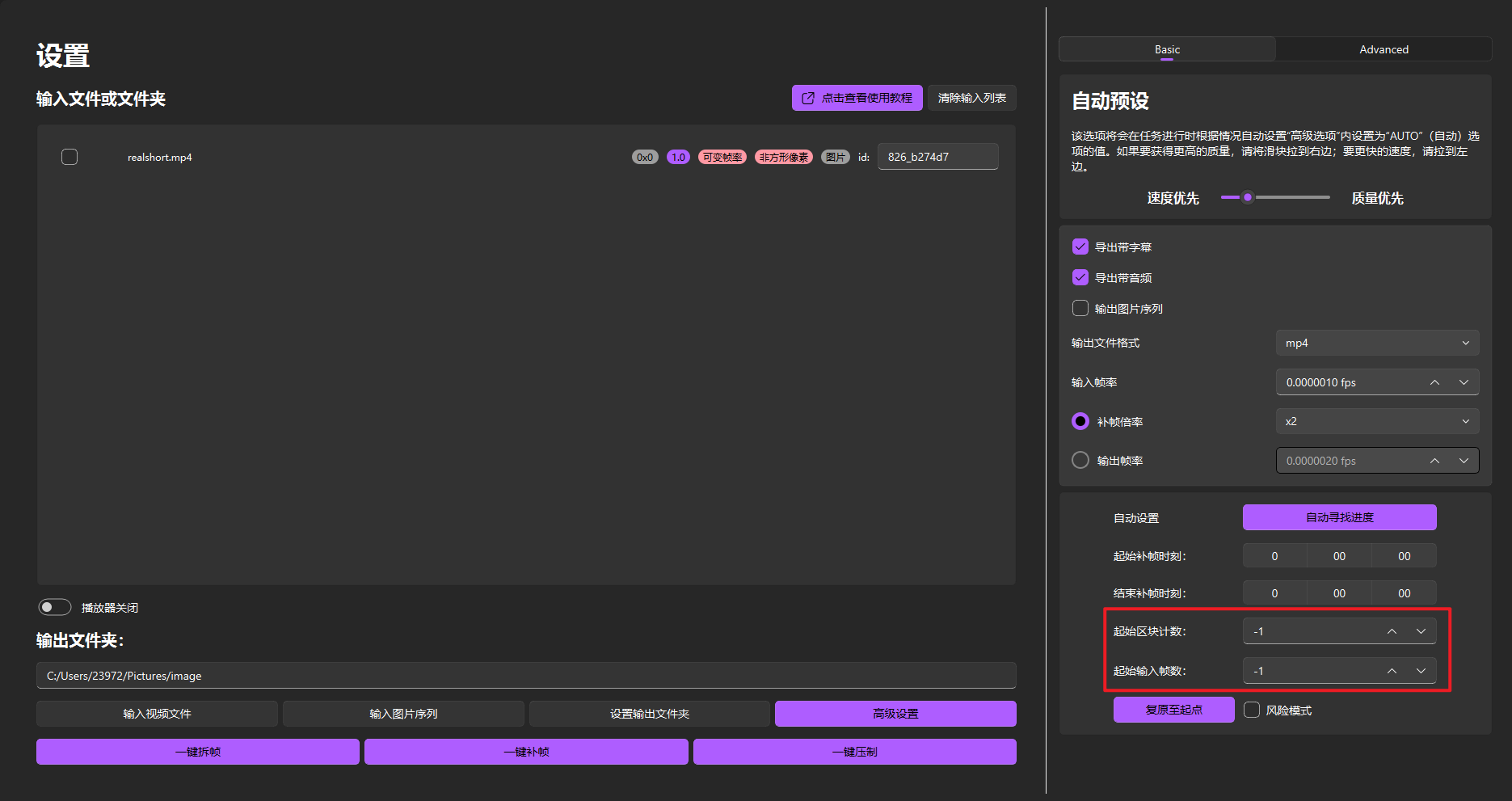
如上图,一个视频chunk有1000帧
复原至原点
将起始区块和起始输入帧数归为系统默认值,软件将自动搜索复原点并恢复任务进度
风险模式
需要恢复任务进度时,开启此项可以减少程序恢复进度所需的时间,但开启可能会造成音画不同步。
不推荐开启。
软件高级设置
转场识别
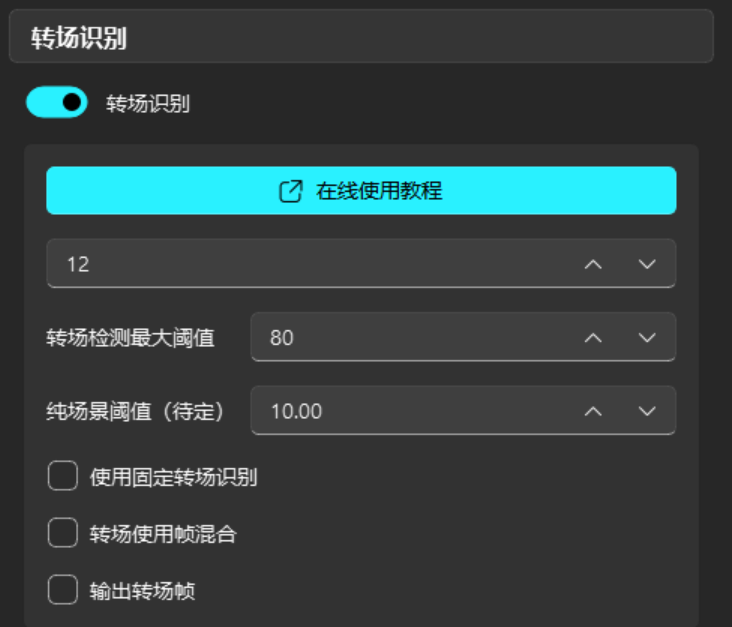
开启转场识别
识别场景切换
为了在补帧过程避免场景切换时产生果冻效应,建议您开启转场识别。
在勾选了开启转场识别之后,下方的参数值一般选择12;如果您发现最终导出的视频比较卡顿,可以考虑调节至15;
如果发现果冻效应较多,可以考虑将参数值调到9,参数值的范围一般为9-15。
如图:转场漏判产生果冻

注意
由于该转场识别机制基于长视频输入设计,因此对于一些短视频输入(2-3s),建议关闭该转场识别功能或手动使用第三方软件生成转场数据实现手动转场处理,避免自动识别性能较差导致卡顿。
最大识别阈值 (默认不用调整)
当没有开启 使用固定转场识别 时(默认情况),该选项建议值为80-90。
当开启 使用固定转场识别 时,该选项建议值为40-60。
使用固定转场识别
使用固定的阈值(最大识别阈值)来识别转场(不稳定),此时软件将对视频每两帧进行一次相似度检测,
如果相似度大于该阈值,则认为是转场帧。该模式很容易导致误判或漏判,仅建议在默认转场检测方法漏判较多时使用,如镜头非常多的混剪。
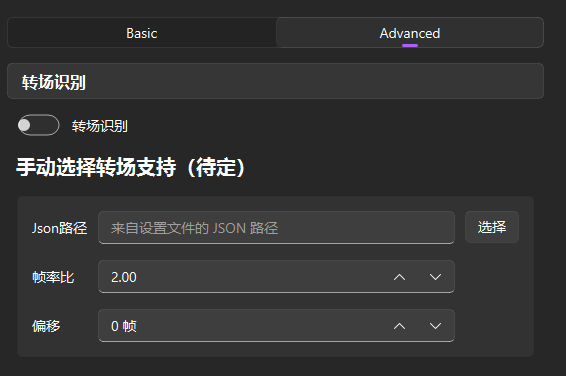
手动选择转场支持
关闭“转场识别”按钮时显示
Json路径选项填写 Transition Chooser 导出视频转场列表文件的路径,见使用教程。
该方法能够导入使用TC软件手动标记的转场替换自动识别的转场,来手动实现对输入视频何处补帧何处不补的完全控制。
其他转场检测设置
输出转场帧
输出视频中的转场帧。
转场帧将附带相关判决信息,以png格式输出在项目文件夹的scene文件夹中。项目文件夹会被保留
转场使用帧混合
传统方法是复制前一帧作为转场帧。该方法是混合前后两帧(渐变)以减少复制转场帧导致的卡顿。
转场外插
传统方法是复制前一帧作为转场帧。该方法是使用转场帧的前两帧,使用补帧算法进行外插,以减少复制转场帧导致的卡顿。
注意
不建议使用RIFE算法时开启此选项,否则会引入果冻。
输出分辨率设置
输出文件分辨率
下拉框用于分辨率预设选择。
在预设为Custom(自定义)时,您能够设置视频最终的输出分辨率。SVFI会先对画面的分辨率进行调整,之后再进行补帧。
裁剪黑边
可用于裁剪视频中的黑边,需要手动指定宽高。
注: 若使用AI超分, 则这里的视频指最终的输出视频例:视频注分辨率3840x2160, 实际画面分辨率3840x1620, 则在此处的高填
270 = (原片高-实际高)÷2。
例:输入视频1920x1080,实际分辨率1920x800,超分2倍输出3840x1600。则黑边高填280, 输出分辨率可自定义为3840x1600
提示
若宽和高都输入-1,SVFI将自动识别输入视频的黑边并裁剪
处理后补全黑边
切除黑边后进行处理(补帧或超分),补完帧后再把黑边自动加回来。
提示
一定程度上可减少单帧计算量,加快处理速度。
使用AI超分——使视频画面更清晰
提示
此功能需购买专业版DLC
注意
同时进行补帧超分会消耗更多显存,显存不足可能会导致任务失败。
若显存少于10G,建议先使用一键压制完成超分,再进行补帧。
先进行补帧后超分
先执行补帧操作, 之后进行超分(这通常会降低速度, 但会减小显存占用且往往能获得更好的效果)
负载显卡
指定使用哪一张显卡进行超分
超分算法介绍
其他超分选项介绍
超分模型倍数
当前选择的模型的超分倍数
转移分辨率比
即预缩放功能:先按用户设置的百分比缩放原视频,之后再进行超分
例:原视频:1920x1080,转移分辨率比:50%, 模型放大倍数:4x
此时软件的运行过程为:
1920x1080(输入) ->960x540(下缩放50%) ->3840x2160(超分辨率)
提示
- 对于恢复模型,转移分辨率会被强制设置为100%。
注意
- SVFI对每帧只会进行一次超分或恢复处理,意味着当用户设定输出分辨率为
400%但使用2x模型超分时,SVFI只会将原视频使用超分模型超分一次到200%,再用bicubic拉伸到400% - 因此,使用100%的转移分辨率,用2x模型做400%超分,和用4x模型做200%超分的效果,是不一样的
- 超分倍率与模型倍率不一致时,使用切割块可能会导致输出视频花屏
切割模式
某些模型专用,切的越多越节省显存,速度降低
No Tile:不使用切割
1/2 on Width: 横向一分为二
1/2 on both W and H: 横纵各一分为二
1/3 on w & h: 横纵各切三份
1/4 on w & h: 横纵各切四份
RealCUGAN低显存模式
realCUGAN专用,显卡显存不足时使用
None: 不使用低显存模式
Low VRAM Mode: 启用低显存模式,可能会对画面质量造成影响
切割块大小
- 有为显存大小制定的预设,也可以选择自定义调节
遇到显存不足问题的建议操作
- 对于6G以下的显存的显卡,若显存不足直接启用切割块,其他选项保持默认
- 6G以上,尝试不开切割块,开切割模式,如果开到最大(1/4)还是爆显存,关闭此设置关掉并直接开启切割块,依次尝试切割块从大(512)到小的选项
- 4G或以下显存,请启用低显存模式并直接启用切割块
注意
使用realCUGAN时不建议开启
超分强度
仅用于RealCUGAN超分模型系列
对于非TensorRT模型:数值越小越清晰锐利, 数值越大越保守稳定 (推荐数值区间0.5-1.2)
对于TensorRT模型,相反:数值越小越模糊,画面越模糊,上限值为1
超分线程
当拥有多张显卡或发现显卡占用吃不满时可以尝试增加此值(一次增加1)
超分序列长度
仅当选择BasicVSR系列、InPaint等需要多帧输入的算法时有效
- 超分序列长度越大,单次超分输入的帧就越多,纹理越稳定,但同时会增大显存占用,
- 建议该值保持10以上,如果显存不足建议降低画面分辨率并保证该值在5以上
- 对于去水印(InPaint)模型,此值普遍建议在30及以上以获得较好的去水印效果
超分使用半精度
- 推荐开启,可大幅度减小显存占用,对画面质量影响较小。
警告
使用NVIDIA 10xx系列Pascal架构的显卡时开启该选项,会减慢超分速度,并可能导致输出黑屏。建议关闭该选项。
TTA
仅ncnnCUGAN支持,以大量时间消耗换取画质的小幅度提升
使用AI增强算法
提示
该功能仅在公测Beta版本中可用
FMNet - SDR2HDR10: 使用AI算法将SDR视频转换为HDR10
DeepDeband: 使用AI算法去除色带(这可能会导致画面颜色变粉)
输出设置(压制参数质量)
渲染质量CRF
用于调整视频导出时的质量亏损, 与输出码率呈正相关。
使用不同压制编码和压制预设均会对CRF产生影响。
CRF数值参数一般为16,此时肉眼无损;
对于H.265编码,码率会有明显下降。请以肉眼所见画面质量来评定CRF数值大小是否合理。
如果是作为收藏CRF数值参数可设为12。
CRF的数值越小,操作过程之后对画面损失就越小,同时导出的成品视频体积(码率)越大。
注意:相同数值,不同编码器的输出质量不同
提示
调整输出视频码率时,如果对CRF不太了解,请使用默认参数16或者通过百度学习相关知识。
目标码率
作为替代渲染质量CRF的可选项,和Primier Pro,After Effects,DaVinci Resolve的设置标准基本相同
编码器
- AUTO
根据软件下方的滑动条自动决定编码器选项 - CPU
选择此项压制,质量最高,但CPU占用率也最高。CPU的性能优劣决定补帧或超分过程中是否会阻塞(导致显卡占用下降),以及最后操作完成的时间长短。 - NVENC
此项仅供支持NVENC功能的NVIDIA显卡选用,如果您的显卡并不支持NVENC功能请不要选择此项。
请自行查阅安装目录下的NVIDIA NVENC Gen.pdf查阅自己的显卡是否支持NVENC - VCE
此项仅供支持VCE功能的AMD显卡选用,如果您的显卡并不支持VCE功能请不要选择此项。 - QSV
此项仅支持有Intel核显的用户选用(例如Intel UHD 630、IrisPro 580),非此类用户不要选用。
提示
以下编码器需购买专业版DLC
- NVENCC为NVENC的优化版本,处理速度更快,作品质量更好。
- QSVENCC为QSV的优化版本,完成任务的效率更高。
- VCENCC为VCE的优化版本,完成任务的效率更高。
手动指定硬件编码器使用的GPU
在高级设置的自定义压制命令行选项中,
- 使用encc编码器,填写
-d||<gpu>来控制使用的编码GPU,如-d||0 - 使用ffmpeg nvenc编码器时填写
-gpu||<gpu>来控制使用的编码GPU - 使用ffmpeg vce,qsv编码器时填写
-init_hw_device||qsv=intel,child_device=<gpu>来控制使用的编码GPU
感性对比:
| 编码器 | 使用硬件 | 速度 | 质量 | 文件大小 | 选择建议 |
|---|---|---|---|---|---|
| CPU | CPU | 中 | 高 | 中 | 追求画质和编码稳定性以及A卡用户AU用户选择 |
| NVENC | N卡 | 快 | 中 | 大 | 追求速度和质量并重,对大小不太敏感的用户选择 |
| QSV | Intel核显 | 快 | 中 | 大 | 追求速度和质量并重,对大小不太敏感的用户选择 |
选择压制编码
对于此项功能的选择,需要您具备一定的视频压制常识。
如您不熟悉压制,请您谨记以下规则:
- HDR输出务必选择H.265 10bit编码
- 2K以上分辨率务必选择H.265编码:尤其是4K,8K分辨率
- 如果H.264、H.265编码均出现问题,使用ProRes编码。此编码输出最贴近肉眼无损,码率极大,是用于剪辑工作的中间编码格式。
- 推荐使用H.265 fast编码或ProRes编码
- 当出现
Broken Pipe错误时,请直接使用H265编码。请注意上述编码存在最高分辨率和帧率的限制, - 请不要刻意同时追求过高的分辨率和帧率:如8K 120fps
提示
- CPU 编码即为软件编码,软编普遍速度慢文件小、质量好。
- NVENC 、QSV、VCE 为硬件编码,其中NVENC 使用nVidia显卡,QSV 使用intel 核显,VCE使用AMD显卡,硬件编码的特点,速度快、文件大,在低码率小文件的情况下,质量比CPU 差。
- 硬编优先选择NVENC,在N卡硬编预设(您可以鼠标悬浮看说明)这一项中,可以自行在驱动官网查询自己显卡的硬编预设等级,20系和30系一般都为7th+。
- 硬编会对显卡有一定负载,如果选用NVENC 出现Broken Pipe错误,请降低N卡硬编预设或者换用核显编码QSV。
- 如果仍有同样错误,使用CPU。
其他的一般性建议
- 如果输出仅用于个人观赏用途,对压制质量要求较低,请尽量使用硬件编码(NVENC,VCE,QSV等)以避免CPU压制瓶颈。CPU瓶颈会导致显卡占用率下降,进而导致任务速度下降
选择压制预设
CPU: 英文含义速度越快的作品质量越低,反之质量越高。
NVENC(N卡专用): 建议无脑选p7
QSV(Intel显卡专用): 直接选slow
VCE(A卡专用): 直接选quality
NVENCC(N卡专用): 直接选quality
QSVENCC(Intel显卡专用): 直接选best
VCENCC(A卡专用): 直接选slow
使用零延迟解码编码
仅当选择压制编码处为H264或H265时有效
使用此功能可以减小视频解码压力, 适用于要求快速解码与低延迟需求的场景, 如:
- 向BiliBili与Youtube等平台上传视频作品时,避免卡转码
- VR头显播放超清超高帧率内容时
- 播放器解码花屏
注意
输入为HDR时此功能不生效
N卡硬编预设
选择NVENC编码器时, N卡硬编预设可在画面质量不变的情况下,缩小导出视频体积,需要查询自己的N卡是第几代NVENC压制芯片,超过7th直接选7th+
默认压制方案
使用传统的压制方案, 兼容性强, 导出视频体积可能会增大。
提示
启用此功能可以解决大多数broken pipe问题。
二次压制音质
- 对音频进行重编码,一般在上传平台的视频上使用
- 将视频中的所有音频轨道压制为640kbps的aac格式。
HDR严格模式
用严格预设处理HDR内容,默认开启即可
兼容 DV HDR10
在杜比视界输出时启用HDR10兼容,默认开启即可
一键HDR: 将SDR视频转换为HDR10+
四种一键HDR模式需要自行尝试效果
解码质量控制
使用VSPipe前置解码
提示
此功能需购买专业版DLC
使用vspipe作为前置解码,此功能是许多特定功能(例如去色块,快速添噪,QTGMC去隔行)的前提条件,
如果您发现他无法解码输入或任务报错,请关闭该选项
提示
可以自行修改软件安装目录的vspipe.py模板文件,以添加自定义滤镜,如dpir等。也可以基于其修改使用VSPipe超分和补帧的顺序
全VSPipe工作流
提示
此功能需购买专业版DLC
全流程使用vspipe进行处理,减少不必要的计算。是当前SVFI相同设置下,能够达到最快速度的模式。
只支持TensorRT加速的超分和部分补帧模型。
若开启此设置进行补帧,会强制开启时空线性化流畅度优化。
硬件解码
可以减轻大分辨率视频解码压力,但可能会在一定程度上降低画面质量,并在显存紧张时导致补帧模块爆显存。
快速拆帧
快速拆帧操作可以减轻解码压力,但可能会导致画面色彩出现偏差。
高精度优化工作流
提示
此功能需购买专业版DLC
- 若CPU性能过剩,建议您开启此项功能,可解决多数画面颜色偏差问题,并可最大程度解决HDR视频压制产生的色偏问题。此功能会加大CPU负担,甚至影响补帧速度。
- 超分工作开启此功能将会关闭半精度(所需要的显存更大)。请您酌情选择。
提示
建议在输入HDR视频时开启此选项
开启反交错
提示
此功能需购买专业版DLC
使用ffmpeg对输入的隔行扫描视频进行反交错处理。
当使用vspipe前置解码时,使用QTGMC反交错处理画面
快速降噪
提示
此功能需购买专业版DLC
此栏目下的“快速”选项如果不是特殊需要,请保持关闭,否则会减缓任务处理速度。
提示
推荐自行控制变量试验此选项是否对画面质量提升有帮助。
与高精度优化工作流不兼容
快速添噪
为视频添加噪点,常用于视频超分时
自定义拆帧参数 (专业选项)
用于替换ffmpeg或vspipe用于解码的参数,自定义参数之间用||间隔
自定义编码设置
指定编码线程数
编码器为CPU时,有几率控制CPU占用率以控制渲染速度。
自定义压制参数
此功能为专业选项(注意输入项数必须为偶数),
键值之间用||分隔
例 CPU h265压制时自定义压制参数:
-x265-params||ref=4:me=3:subme=4:rd=4:merange=38:rdoq-level=2:rc-lookahead=40:scenecut=40:strong-intra-smoothing=0
还可以添加pools="8,8,8,8"以指定核心编程数目
时间重映射: 改变视频的速度
提示
此功能需购买专业版DLC
此功能用于制作“慢动作”素材。
例如设置输出帧率为120帧,时间重映射设置为60帧,输出效果等同于50%播放速度慢放。
其他情况依次类推,您可以自己设置输出帧率,支持小数。
首尾循环
在第一帧放入最后一帧以适配一些首尾相连的循环视频
提示
在一般情况下,结尾因为没有可以补出来的新帧,漏掉(输出帧率/输入帧率)的帧是正常的。但在loop模式下不受影响,因为总有开头帧可以和结尾帧作为补帧对补出剩余的帧
IO控制
手动指定缓冲区内存大小
若运行内存紧张(16G以下),建议手动指定缓冲区内存的大小为2-3G避免爆内存(out of memory)错误。
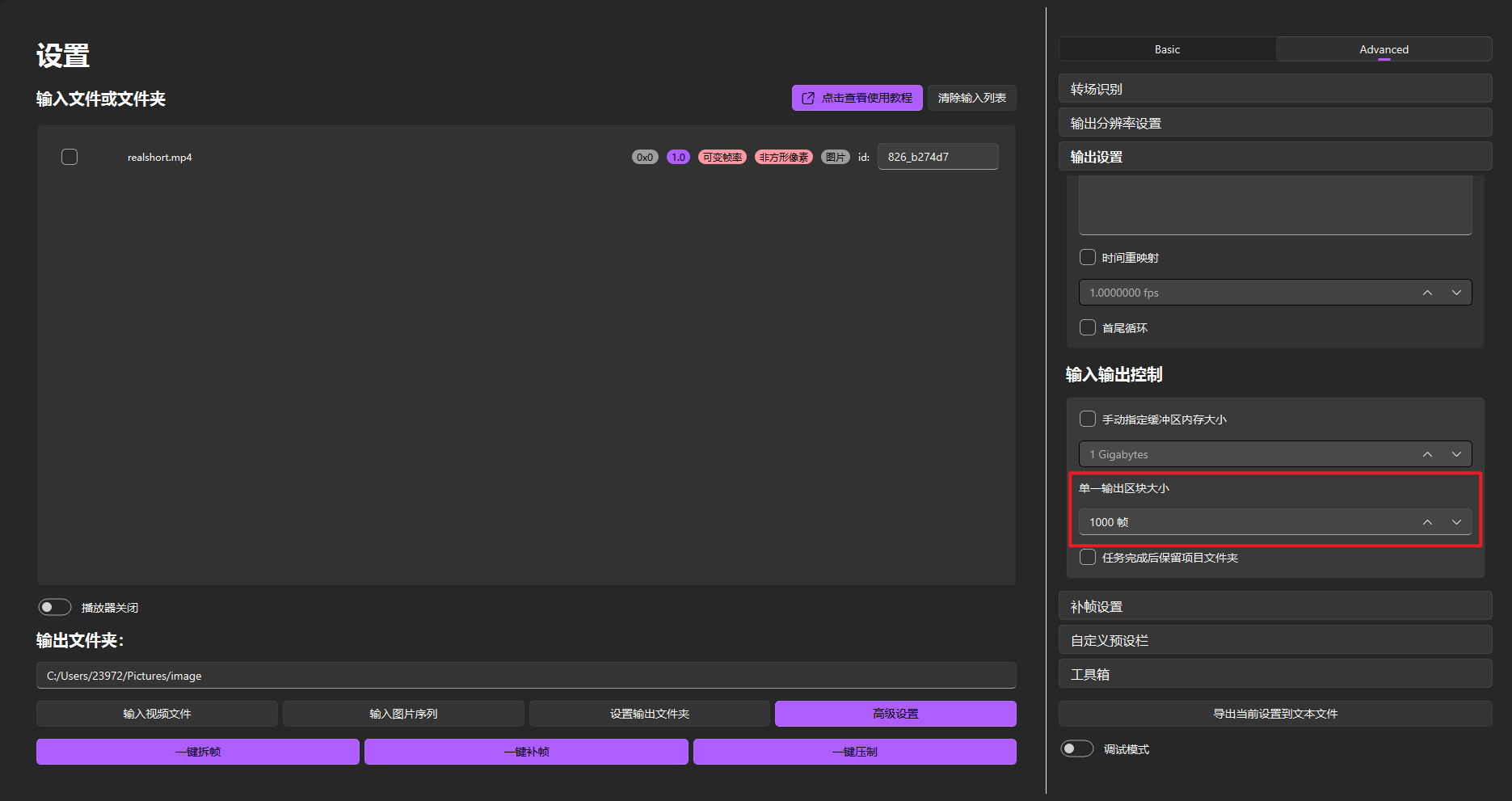
单一输出区块大小
- 对于补帧和压制任务,每渲染数量为该值的帧,将输出一个不带音频的小片段,以方便您预览效果。
- 片段会生成在您设置的输出文件夹中,并在补帧或压制任务完成后合并为一个文件。
任务完成后保留项目文件夹
任务完成后不删除项目文件夹。
补帧设置
安全帧率
如果视频要上传到相应媒体平台上在线观看,请开启此项。
该选项会在输入为NTSC制式视频时(如24000/1001帧率的视频),将输出正确转换为对应的NTSC制式视频(如60000/1001),以避免音画不同步。不开启则可能会音画不同步(如输出是59994/1000)。
建议保留此项开启
注意
若不开启该选项,在输入为非标准帧率下(如119800/1000)输出mkv可能会由于mkvmerge的原因导致输出变为可变帧率视频。
尽量使用标准输入帧率的视频进行处理以避免音画不同步
半精度模式
可以降低显存占用, 对于20系, 30系, 40系及以上的NVIDIA显卡有加速效果
注意
可能会导致画面精度下降。
如,使用gmfss模型进行补帧时可能导致输出视频出现颗粒感
反向光流
该功能可使画面在一定程度上更加丝滑。
提示
若使用GMFSS pg 104补帧模型时出现cudnn status error错误,请关闭反向光流
开启此功能可能会导致部分模型(如Gmfss pg104)在移动物体周围产生伪影。需要自己反复实验后选择性开启或关闭。其他类似功能同理。
光流尺度
这是SVFI在使用补帧算法进行光流计算时,使用的光流分辨率放缩尺度。0.5说明将输入画面放缩二分之一倍后进行光流计算,以此来提高某些算法的性能或效果。
使用RIFE算法时,当原视频尺寸为1080P时,默认开1.0;4K以及以上开0.5;小于1080P开1.0
使用GMFSS算法时,原视频尺寸为1080P时,默认开1.0;4K及以上开0.5;小于1080P开1.0
注意
使用GMFSS算法,原视频尺寸低于等于1080P时,该选项不建议填写低于1.0的数值
交错补帧
相当于特殊的切割, 用于减少显存占用, 不会出现画面撕裂, 但会使画面模糊
恰当选择此项可以让小显存显卡补超大分辨率(如4G补8K)
视频流畅度优化
注意
该系列选项仅用于动漫输入或存在重复帧的真人素材。
一般情况下真实拍摄的素材不建议开启此选项。
| 方法 | 应用场景 | 速度 | 流畅度 | 果冻数量 |
|---|---|---|---|---|
| 时空线性化 | 通用 | ★★☆ | ★☆☆ | ☆☆☆ |
| 固定阈值去重 | 通用 | ★★★ | ★☆☆ | ☆☆☆ |
| 去除一拍二 | 动漫 | ★★★ | ★★☆ | ★☆☆ |
| 去除一拍二与一拍三 | 动漫 | ★★★ | ★★☆ | ★☆☆ |
| 一阶差分去重 | 动漫 | ★★☆ | ★★☆ | ★★☆ |
| 时空重采样 | 动漫 | ★★☆ | ★★★ | ★★★ |
| 前进消重 | 动漫 | ☆☆☆ | ★★★ | ★☆☆ |
| 交叉重建 | 动漫 | ★☆☆ | ★★★ | ★☆☆ |
注意:果冻数量越少,视频质量越好;星越多,算法可能输出果冻的越多
说明:
- 时空线性化: 解决补帧时不对称问题引起的卡顿, 补任何视频都有一定的流畅平稳效果(又名TruMotion)
- 固定阈值去重: 用于缓解重复帧造成的画面卡顿感,一般通用值为0.2,动漫时使用0.5,1.0或更高
- 去除一拍二: 识别并将动画中的一拍二画面变成一拍一
- 去除一拍二与一拍三: 识别并将动画中的一拍三、二画面变成一拍一
- 一阶差分去重: 和去除一拍二与一拍三类似,但是除重更激进
- 时空重采样: 如果输入视频帧率在24左右,并且最多只有一拍三,没有更高节拍的画面,则可以完全去除动漫视频素材的卡顿
- 交叉重建: 和时空重采样类似,总体上效果会更好,输入帧率请一定要在24左右,输出帧率只能是输入帧率的整数倍,且仅供特定模型使用
- 前进消重: 完全去除动漫视频素材的卡顿,如果您输入的视频帧率在24左右,默认填2表示可以解决一拍三及以下节拍带来的卡顿问题
提示
前进消重,交叉重建,时空重采样,仅支持任意时刻补帧的算法与模型
若不清楚自己的视频属于一拍二还是一拍三,请查看一拍N介绍
如果使用去重优化后输出视频还是不够流畅,可能是转场检测导致误判,需要提高转场灵敏度阈值
注意
由于现阶段AI补帧在动漫补帧方面能力有限,选择去重将加大帧间运动幅度,导致补帧时产生画面扭曲,请自行对于每个输入视频控制变量多次试验选择最好的除重模式。
建议您谨慎选择去重模式,如果对动漫全片进行补帧,建议开时空线性化或者不开启去除重复帧。
开启视频流畅度优化后(前进消重)补帧效果如下


负载显卡
指定使用哪张显卡进行补帧
补帧算法介绍
其他补帧选项介绍
TTA模式
提示
此功能需购买专业版DLC
开启该功能可以减少画面果冻,减小字幕抖动,减弱物体消失的问题。使得画面更加平滑舒适
需要额外消耗补帧时间,同时部分补帧模型不支持此功能。
后面的数字填的越大越慢,果冻越少,一般填1或者2即可
中向,适合rife2.3
双向光流
速度降低一半左右,RIFE 2.x系列补帧模型效果可能会有些许提升
gmfss/umss模型开启双向光流能加速5%, 效果不会变化, 但会增加显存占用
动态光流尺度
提示
此功能需购买专业版DLC
在补帧过程中动态选择光流尺度,可减少物体消失问题以及减少果冻 (仅适用于RIFE 2.3与RIFE 4.6)
自定义预设栏
提示
此功能需购买专业版DLC
基于当前设置新建预设
在给预设取个名字之后点击即可新建预设
移除当前预设
删除当前选中的预设
应用指定预设
加载之前保存的预设,自动载入参数
工具箱
结束残留进程
将结束所有任务,包括多开SVFI的任务。
提示
如果需要避免结束多开SVFI的情况,需要手动在任务管理器中,结束当前SVFI进程下的所有SVFI CLI进程。在开启多线程时,始终建议不要轻易点击结束任务按钮。
视频转换 GIF 动图
生成高质量的 GIF 动图
使用范例:
输入视频路径:
E:\VIDEO\video.mp4输出动图(gif)路径:
E:\GIF\video_gif_output.gif输出帧率: 30 fps
提示
输出帧率一般要小于等于原视频的帧率, 不建议高于30
合并已有区块
将散落的chunk片段合并。
提示
若任务在最后的合并期间失败,可以在调整设置后直接选中任务并点击此按钮完成合并操作。
音视频合并
填入视频的完整路径(例
D:\01\myvideo.mp4)填入视频的音频路径(例
D:\01\myvideo.aac), 或者使用一个视频来输入音频(例D:\01\otherVideo.mp4)输出视频路径(例
D:\01\output.mp4)二次压制音频: 将音频压制为aac格式, 640kbps
高级选项下方设置
导出当前设置到文本文件
导出设置信息为ini文件, 可分享给其他用户方便贡献自己的设置。使用方法直接拖入软件内, 会提示成功应用预设。
详细用法见使用技巧。
提示
若软件视频输出不符合预期,如存在偏色,效果不好等情况,可点击此按钮并将设置文件发送给开发者以定位问题。
恢复默认设置
恢复高级选项区域默认设置,该设置不会影响偏好设置区域的设置。
全局设置
当前任务列表所有任务应用同一个设置,以启动任务前高亮的任务设置为准。
调试模式
在任务进行时输出调试信息。
注意
有些情况下该模式会往画面中添加调试内容并让任务处理速度变慢。
因此在正式处理任务时请关闭该选项
涡轮增速
对现有工作流进行加速,提高任务处理速度。
提示
此功能需购买专业版DLC
提示
仅NVIDIA显卡支持,部分功能、模型使用存在限制
左侧标题栏功能
设置
主设置页
预览
输出预览页
提示
在使用播放器界面进行预览时,若输入为HDR视频,则预览画面发灰是正常现象。
状态
查看程序输出信息
用户页
查看已获得的软件成就与可扩展或已拥有的DLC
偏好设置
休息间隔
每隔 X 小时让设备休息15分钟,期间暂停任务
缓存文件夹
将任务文件夹指定到其他位置。最终输出视频将仍在目标文件夹
任务运行后
可以选择一些补帧完成后的自动操作
强制退出
默认开启, 软件出现错误时强制结束软件进程, 避免出现残留进程
提示
在需要使用SVFI的多开/多实例功能或one_line_shot_args管道功能时,建议将此选项关闭以避免软件结束后强制退出导致实例也被强制退出。
启用预览
补帧时开启预览窗口
自动纠错
自动修改设置来防止任务报错
提示
关闭自动纠错能够提升任务初始化速度。建议在使用稳定设置进行队列任务处理时关闭此选项。
特别地,若编码选项或补帧选项设置值存在“AUTO”选项,那么即使该选项处于关闭状态,自动纠错也会执行。
建议将所有选项值设置为非AUTO值以彻底关闭自动纠错。
自定义输出文件名格式
可以自定义输出的文件名。默认值为{INPUT}-{RENDER}.{16BIT}.{DI}.{DN}.{FG}.{DB}.{DP}.{OCHDR}.{FN}.{FPS}.{VFI}.{DEDUP}.{SR}.{FP16}.{DEBUG}_{TASKID}{EXT}。各缩写含义如下:
| 缩写 | 含义 |
|---|---|
| INPUT | 输入文件名 |
| RENDER | 开启仅压制模式 |
| 16BIT | 是否开启高精度模式 |
| DI | 是否开启反交错 |
| DN | 是否开启降噪 |
| FG | 是否开启快速加噪 |
| DB | 是否开启去色带 |
| DP | 是否开启镜头平稳 |
| OCHDR | 是否开启一键HDR |
| FN | 是否开启FMNet HDR |
| FPS | 输出帧率 |
| VFI | 使用的VFI模型 |
| DEDUP | 重复帧去重模式 |
| SR | 使用的超分模型 |
| FP16 | 是否开启半精度 |
| DEBUG | 调试模式 |
| TASKID | 任务ID |
| EXT | 输出文件扩展名 |
提示
至少要包含{INPUT},否则无法识别任务。
完成后清空任务列表
列表中所有任务完成后清空输入队列
静音模式
不弹出窗口与通知
窗口置顶
让窗口保持顶部以避免可能的Windows调度性能损耗
背景图片
可选择图片开启自定义背景
背景模糊
值越大背景越模糊
背景透明度
值越大背景亮度越高
经典高级设置布局
使用SVFI 3.x版本的竖向高级设置布局
应用主题
更改应用程序的主题
主题颜色
更改应用程序的主题颜色
语言
为用户界面设置首选语言
添加白名单
点击按钮以将安装文件夹添加到Windows Defender白名单。此操作对其他杀软无效。
检查安装文件完整性
点击按钮以在下次启动时,通过Steam检查文件完整性。可能可以修复一些软件更新或者错误设置导致的软件无法正常运行的问题。
仅使用 CPU
仅使用CPU进行AI推理。只适用于无显卡设备。
使用所有 GPU
使用所有可用的GPU进行AI推理加速。
注意
如果设备只有一张显卡,请务必关闭此选项。
TensorRT INT8 量化功能
加速TensorRT模型的运行速度, 但编译TensorRT时会耗费更多时间, 且可能导致模型效果下降, 请谨慎使用该功能。
软件默认会对模型进行750轮量化,量化次数可在进阶相关设置调整。处理时间较久,且可能在部分设备上加速不明显。
帮助
了解SVFI的新功能和实用技巧 (快捷操作,快捷键等)
提供反馈
提供反馈意见, 帮助我们改进SVFI
隐私保护声明
点击按钮以确定是否发送不含隐私的诊断数据以帮助我们改进软件。
关于
软件版权与日志