Model Specification
The following content is the specification and usage case of each AI model integrated in the software
Introduction to Video Frame Interpolation Algorithms
SVFI integrates several frame interpolation algorithms, such as RIFE, GMFSS, UMSS, etc.
These algorithms perform differently on different genres of input, and the algorithms and models for In-Real-Life and In-Game/Animation footages are respectively shown in Presets and the following introduction
Introduction to Frame Interpolation Models
- RIFE: High-speed, popular frame interpolation algorithm
4.25+: The newest algorithm, suitable for most real-life interpolation scenarios.
4.18: With bidirectional and dynamic optical flow enabled, real-life interpolation quality may exceed that of 4.25.
rpr_v7_2.3_ultra: 3rd Gen Combined model, more adaptable to complex scenes.
rpr_v7_2.3_ultra#2: Combined model, more adaptable to complex scenes.
4.6-4.7: 2nd Gen models. The speed is more than twice as fast as 2.3, the effect is better, and it is recommended to use.
4.8: Anime material optimization model, the effect of interpolating anime is better, and the speed is the same as 4.6
4.9: Anime and live-action material optimization model, the effect of interpolating live-action is better, and the speed is the same
2.3: 1st Gen model, Classic, slow speed, good effect, but not compatible with some options.
Tips
Models with the ncnn prefix use ncnn as the forward reasoning framework, which is compatible with NVIDIA GPUs and AMD GPUs, and models without this prefix cannot be used for AMD GPUs and core displays.
ncnn-rife: RIFE with support for various graphics card versions, good compatibility, fast speed, and slightly worse quality than RIFE.
GIMMVfi: A good VFI model GIMM-VFI
GMFSS: Slow speed, super high quality (the following is the model introduction) (models with the trt mark are acceleration models)
pg104: Newest gmfss anime model, currently the most powerful anime frame interpolation model
Umss_v1: Like pg104, specialized for anime frame interpolation, but slightly slower; in some scenes the output is smoother than pg104 with fewer artifacts.
union_v: stable texture preservation and smooth output
basic: The first-generation gmfss model, slow speed, and the effect may be more stable than
union_v
Warning
The series model consume a lot of VRAM and not recommended for 4K+ resolution interpolation,
please enable "Is SR later than VFI" in the "Use AI SR" settings of advanced settings to perform super resolution and VFI together at least VRAM cost.
- DRBA: VFI model that preserves the original pace of anime
DRBA_RIFE_v4.26: A VFI model that adapts to the original pace of animation, with fast processing speed. When used with turbo mode, it can achieve real-time playback on some GPUs.
DRBA_GmfSs_pg: High-quality export of VFI results that adapt to the original pace of animation, with slower speed but stable performance.
DRBA Demo


The left side of the GIF shows the input, and the right side shows the output. The background (linear motion part) maintains linear motion after interpolation, while the characters (non-linear motion part) maintain their non-linear motion pattern.
Super-Resolution Algorithm
Tips
This feature requires the purchase of the Professional DLC.
Currently, SVFI supports the following super-resolution algorithms.
| Algorithm Name | Applicable Genre | Requires BETA | Available on AMD GPUs |
|---|---|---|---|
| Anime4K | Anime | √ | |
| AnimeSR | Anime | × | |
| realCUGAN | Anime | × | |
| ncnnCugan | Anime | √ | |
| waifuCuda | Anime | × | |
| PureBasicVSR | Live Action | × | |
| BasicVSR++ T3 | Live Action | √ | × |
| ATD | Live Action | √ | × |
| realESR | General | × | |
| ncnnRealESR | General | √ | |
| waifu2x | General | √ | |
| TensorRT(ONNX) | General | × | |
| Compact | General | √ | × |
| SPAN | General | √ | × |
Tips
SVFI defines the distinction between anime materials and live-action materials as follows:
Anime materials are moving video clips mainly composed of flat image layers, and the boundaries between each layer and the other layers are clear. For example, hand-drawn 2D animation, most three-dimensional rendered two-dimensional pictures, etc.
In Real Life (IRL) materials are real-world pictures or computer-generated pictures captured using a single-view camera, and the individual layers and their boundaries cannot be distinguished by the naked eye. For example, live-action movies, 3D CG, 3D game pictures, etc.
In particular, we consider animations made with 3D/3G backgrounds + 2D characters to be in the anime material category.
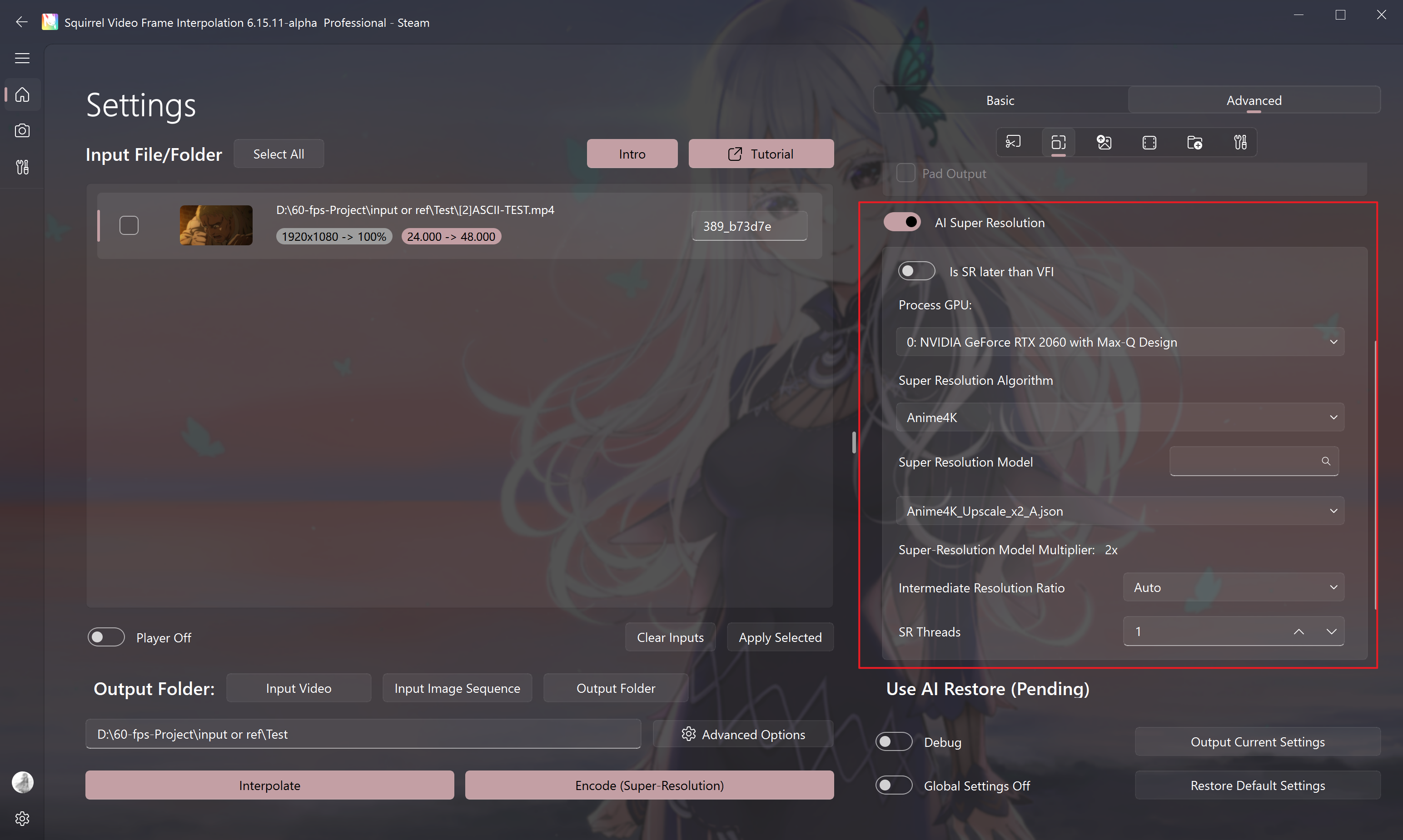
Introduction to the Super-Resolution Model
realCUGAN
Exclusive for anime, the effect is very excellent
up2x represents a 2x upscale, and 3x, 4x, etc. are similar.
The pro model is an enhanced version, see official introduction for details.
Models with the word "conservative" are conservative models.
Models with "no-denoise" do not perform noise reduction.
Models with "denoise" perform noise reduction, and the number behind represents the noise reduction intensity.
ncnnCUGAN
The NCNN version of CUGAN (universal for AMD GPUs, NVIDIA GPUs, and Inte; GPUs), the introduction is the same as above.
realESR
Applicable to both 3D anime, more suitable for anime
The RealESRGAN model tends to fill in the blanks, making the picture clearer and more vivid.
The RealESRNet model tends to smudge, but the picture retains its original color.
Models marked with "anime" are dedicated for anime super-resolution, and the speed is slightly faster than the previous two.
anime is the official model, and anime_110k is a self-trained model.
RealESR_RFDN is a self-trained super-resolution model with fast speed and is suitable for anime input.
ncnnRealESR
The NCNN version of realESR, universal for AMD GPUs, Intel GPUs, and NVIDIA GPUs.
- realesr-animevideov3 (a relatively conservative anime video super-resolution model, with fast speed and high quality)
- realesrgan-4xplus (4x upscale model)
- realesrgan-4xplus-anime (4x anime upscale model)
AnimeSR
An anime super-resolution algorithm developed by Tencent ARC Lab
Only one 4x upscale model (AnimeSR_v2_x4.pth), the effect is more conservative compared to cugan.
BasicVSRPlusPlusRestore
A real-world super-resolution algorithm that depends on the length of the super-resolution sequence for effect.
Tips
This algorithm is only available in the beta version of the public test.
Warning
This series of algorithms consume a lot of video memory, it is recommended to use a graphics card with more than 6G.
- basicvsrpp_ntire_t3_decompress_max_4x 4x upscale deencoding model t3 (recommended)
- basicvsrpp_ntire_t3_decompress_max_4x_trt 4x upscale deencoding model t3 (TensorRT acceleration) (difficult to compile, not recommended)
Anime4K
A super-fast real-time anime super-resolution algorithm, relatively conservative
There are 6 preset scripts in total.
- Anime4K_Upscale_x2 A/B/C/D are all 2x upscales (default is A).
- Anime4K_Upscale_x3 is 3x upscale, and the x4 model is similar.
Custom Anime4K models
- In the installation folder
models\sr\Anime4K\models, you can see the.jsonmodel configuration file. - Take
Anime4K_Upscale_x2_A.jsonas an example.
{
"shaders": [
{
"path": "Restore/Anime4K_Clamp_Highlights.glsl", "args": []
},
{
"path": "Restore/Anime4K_Restore_CNN_VL.glsl", "args": []
},
{
"path": "Upscale/Anime4K_Upscale_CNN_x2_VL.glsl", "args": ["upscale"]
}
]
}Among them,
Anime4K_Clamp_Highlights.glslandAnime4K_Restore_CNN_VL.glslare 1x restoration algorithms, corresponding tomodels\sr\Anime4K\Restore\Anime4K_Clamp_Highlights.glsl. Theargsparameter of this model needs to be left empty.Anime4K_Upscale_CNN_x2_VL.glslis a 2x upscale algorithm, corresponding tomodels\sr\Anime4K\Upscale\Anime4K_Upscale_CNN_x2_VL.glsl. Theargsparameter of this model needs to be filled in withupscale.Similar to the
Anime4K_AutoDownscalePre_x2.glslmodel, theargsparameter needs to be filled in withdownscale.The order of the list is the actual calling order of the filters, and you can observe the model folder to freely combine, edit or create a new
.jsonfile to take effect.
waifu2x
A classic conservative super-resolution algorithm
The cunet model is used for anime super-resolution.
The photo model is used for real-world shooting.
anime is used for anime super-resolution.
waifuCuda: CUDA implementation of waifu2x
Used for anime super-resolution, the speed and effect are somewhat similar to cugan.
Compact
Tips
This algorithm is only available in the beta version of the public test of the professional DLC, and you need to manually go to the Steam settings - beta version to select it.
A super-resolution model structure, some models such as AnimeJanai are trained based on this structure.
AnimeJanai
Applicable to both 3D anime, more suitable for anime
- A weakened version of RealCUGAN, with poor depth-of-field recognition (easy to sharpen the background), less computing power and faster speed.
- Speed: UltraSuper > Super > Compact model.
SPAN
Tips
This algorithm is only available in the beta version of the public test of the professional DLC, and you need to manually go to the Steam settings - beta version to select it.
A super-resolution model structure, some model series such as Nomos are trained based on this structure.
TensorRT
Dedicated acceleration for the NVIDIA GPU of some of the above super-resolution algorithms
- All models of cugan can be accelerated.
- real-animevideov3 is a model specifically prepared for anime video super-resolution in RealESR.
- RealESRGANv2-animevideo-xsx2 2x anime video super-resolution upscale model.
- RealESRGANv2-animevideo-xsx4 4x anime video super-resolution upscale model.
Warning
Since pre-compilation is required for processing using TRT, do not enable more than 1 thread when using TRT encoding for the first time.
If an error occurs when using it for the first time, please try five or six times.
If the error still occurs, please contact the developer.
In theory, the effect is the same as the non-TRT version, but there are differences in individual scenarios.
Visual Comparison Demonstration of Super-Resolution Models








Add Super-Resolution Models on OpenModelDB by Yourself
SVFI supports adding super-resolution model weights that meet the requirements by oneself.
OpenModelDB supports the model structure as shown in the following figure
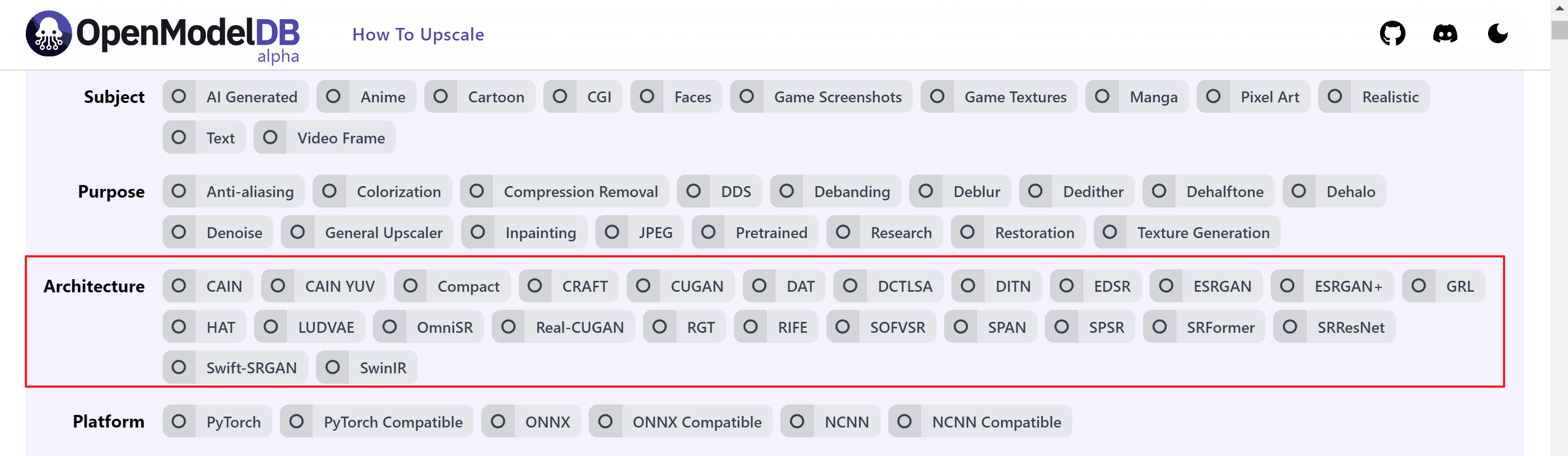
Example: Adding Compact or Compact Model
- Search for Aniscale, and you can see the model to be tested, AniScale-2-Compact
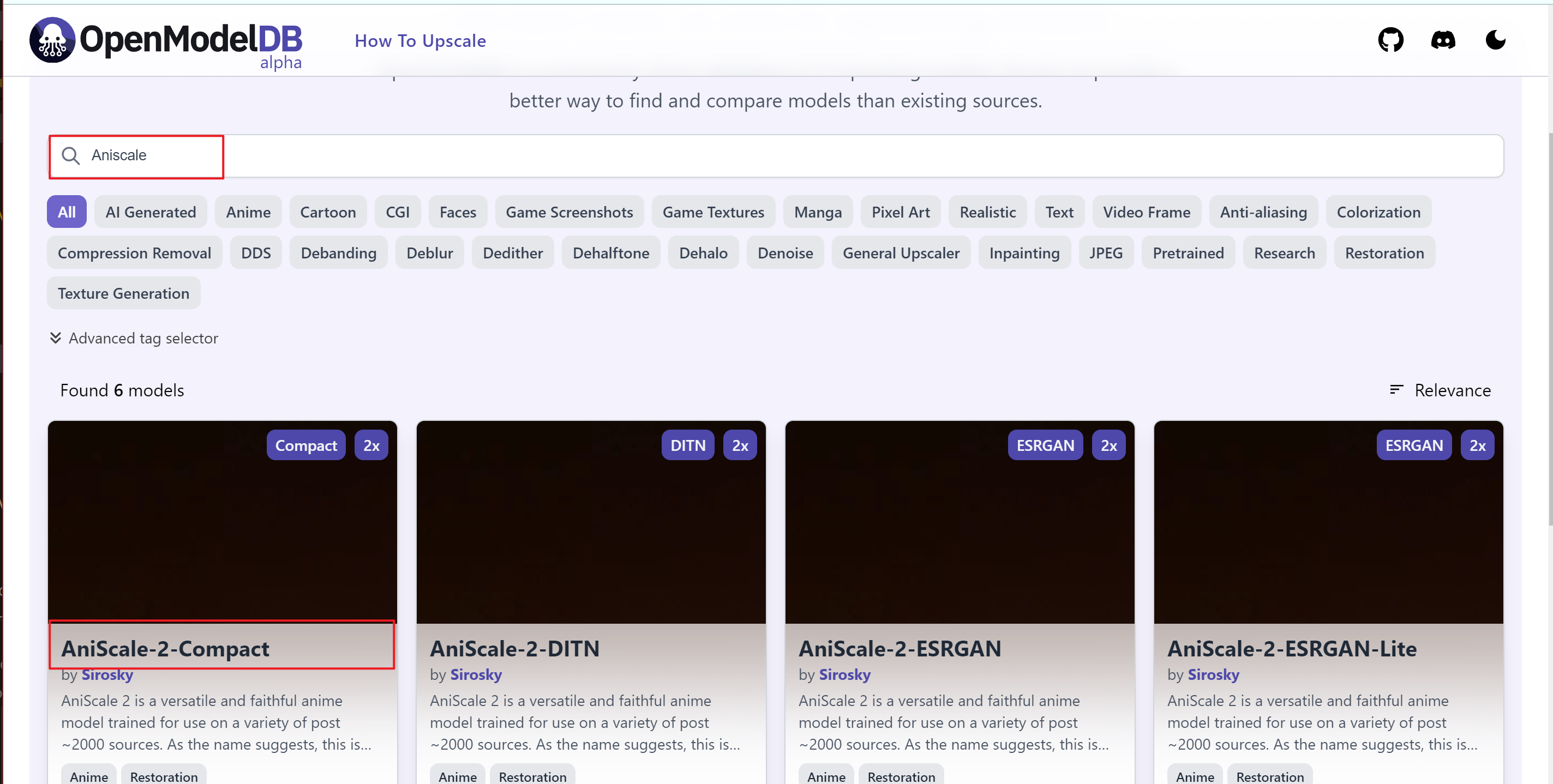
- Click to enter the first generation of Aniscale.
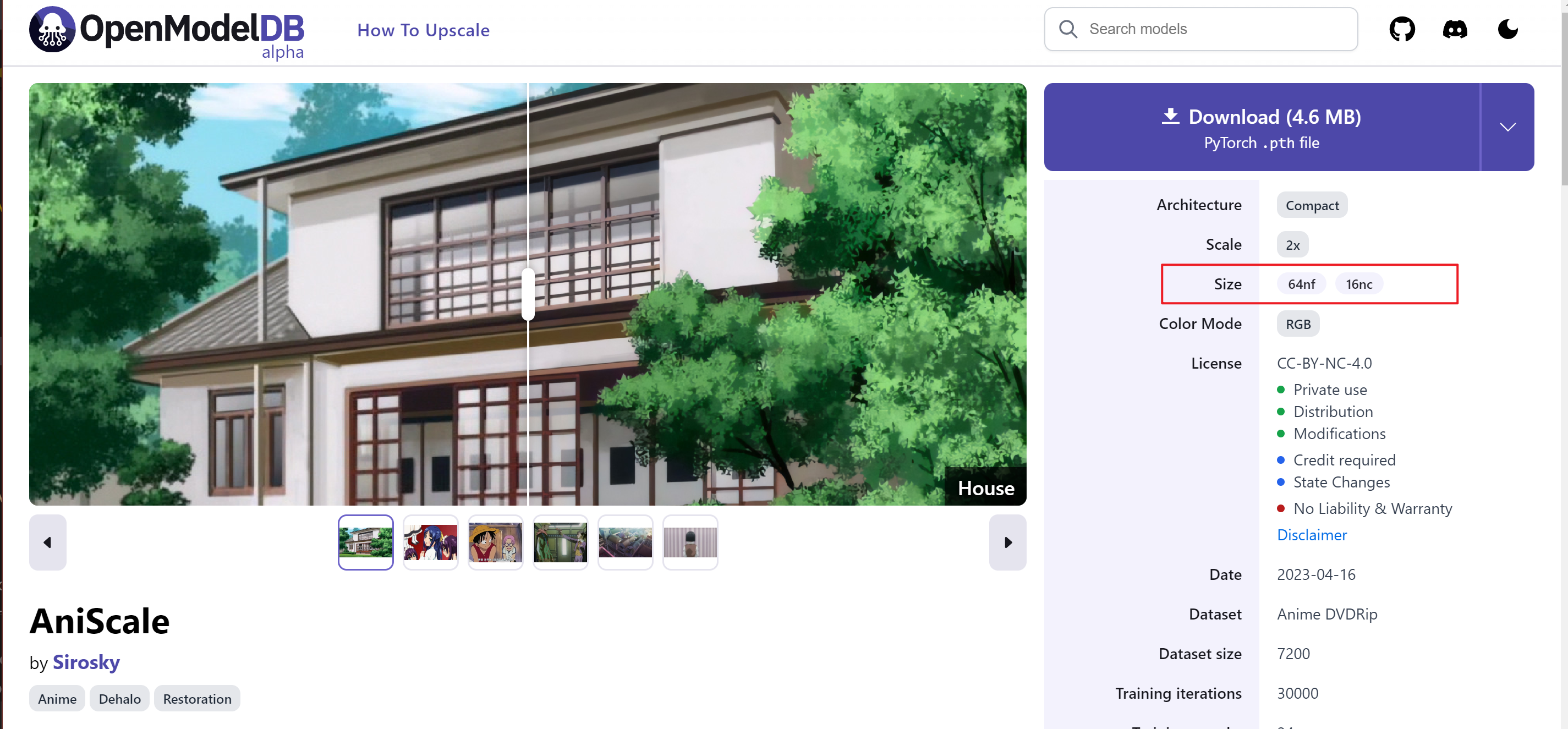
- Pay attention to the model information Size on the right side,
64nfrepresents the number of features ("model channel number"), and16ncrepresents the number of convolutions ("model depth").
The strategy for SVFI to load Compact models is as follows:
- If the model name contains
super ultra(from animejanai),nf=24, nc=8; - If the model name contains
ultra(from animejanai),nf=64, nc=8; - Default
nf=64, nc=16.
- If the model name contains
Looking back at Aniscale-2-Compact, it is found that there is no model information description on the web page, so it is considered that it uses the default model structure configuration,
nf=64, nc=16.Just download the pth model directly to
SVFI\models\sr\Compact\modelsand it can be used. If there is no such folder, please create it manually.The same is true for importing the SPAN model.
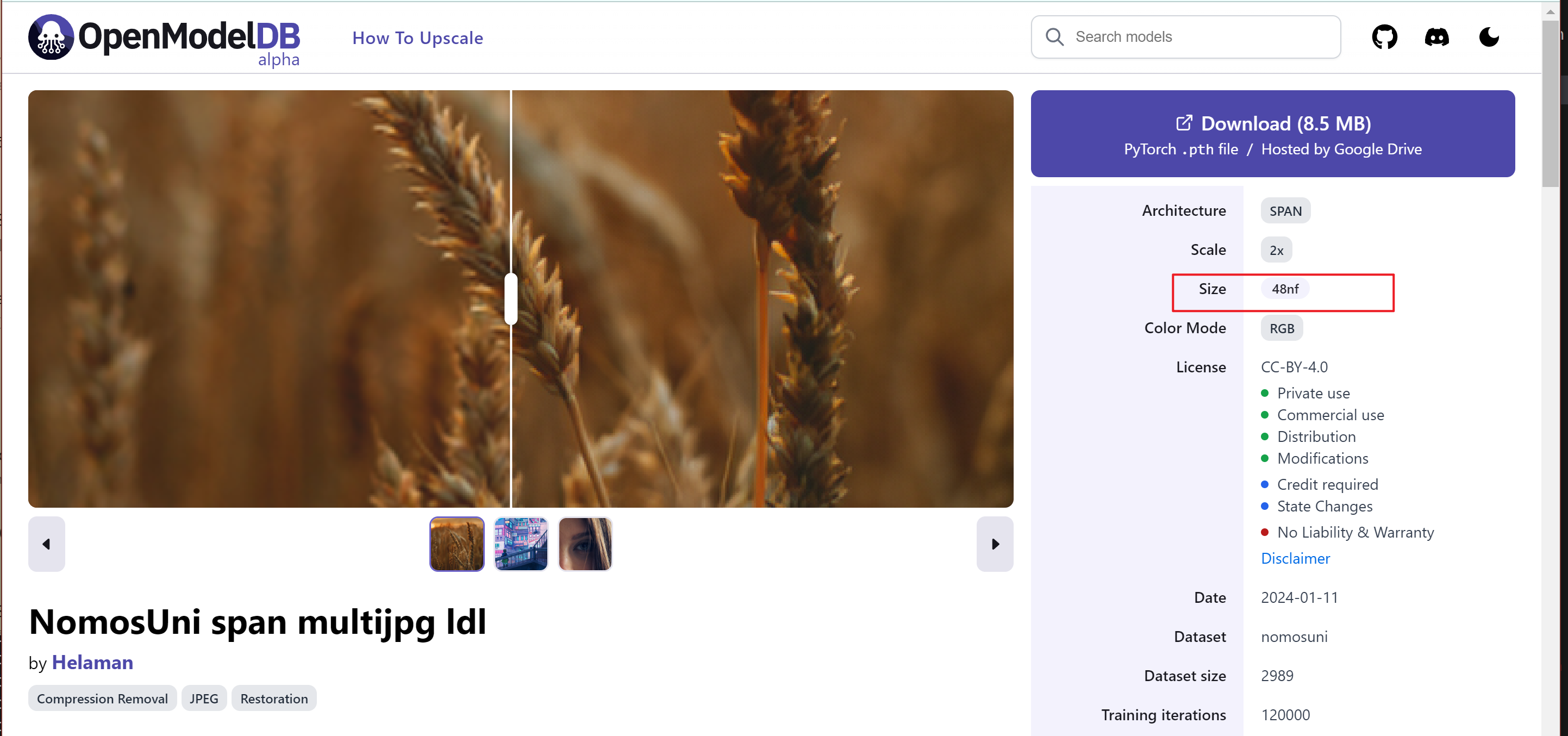
SVFI can currently only load models with nf=48, and other models are not supported for the time being. Other modified models are also not supported.
Example: Adding TensorRT Model
You can also add other supported super-resolution models such as AnimeJanai.
The onnx requirements of the super-resolution model supported by SVFI are as follows:
- There is only one input, and the dimension is
[dynamic, 3, dynamic, dynamic]. - There is only one output, and the dimension is
[dynamic, 3, dynamic, dynamic]. - The input node name is
input, and the output node name isoutput.
Put it in SVFI\models\sr\TensorRT\models.
Model Compilation Instructions
- After the model is compiled, a
.enginefile will be generated. For example,realesrgan_2x.onnx.540x960_workspace128_fp16_io32_device0_8601.engineindicates that the input size (patch size) of the model is 540x960. - Different patch sizes will lead to completely different super-resolution speeds, so the patch block size should be carefully selected, and try not to enable the patch block.
Other Model Rules
- Under the default state of esrgan, only models with
nf=64, nb=23are supported. - When the model name contains
anime,nbwill be recognized as 6.
Terminology Explanation
- nf => number of features,
- nc => number of convs,
- nb => number of blocks
Introduction to Some Special Models Placed in the Super-Resolution Category
InPaint Watermark Removal Model
Tips
This algorithm is only available in the beta version of the professional DLC, and you need to manually go to the Steam settings - beta version to select it.
- inpaint_sttn_1x: Currently, this model only supports one-time restoration and has no super-resolution function. It needs to be used with the mask function:
The activation process is as follows:
- Enable the super-resolution function and select the correct model
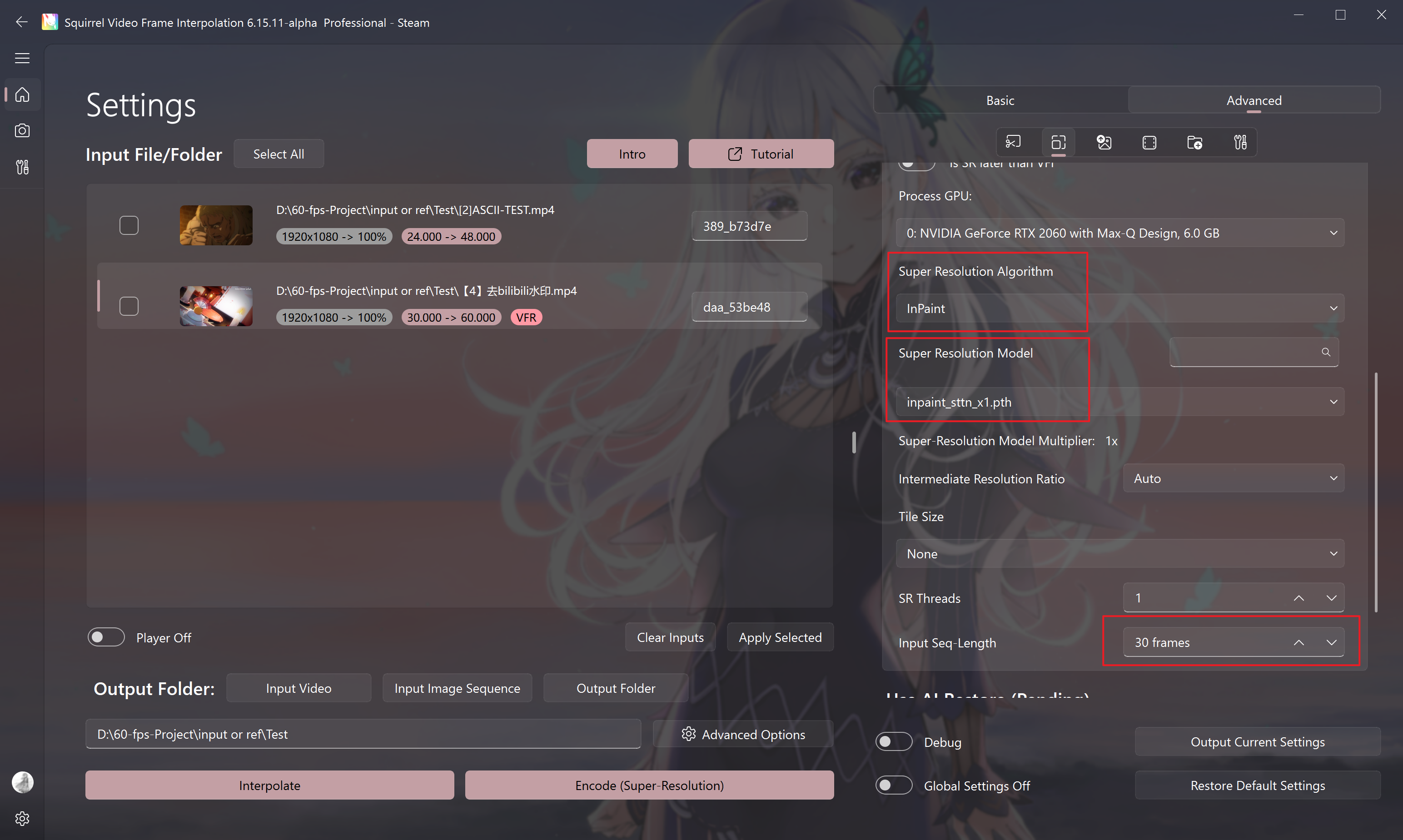
- Enable the player function
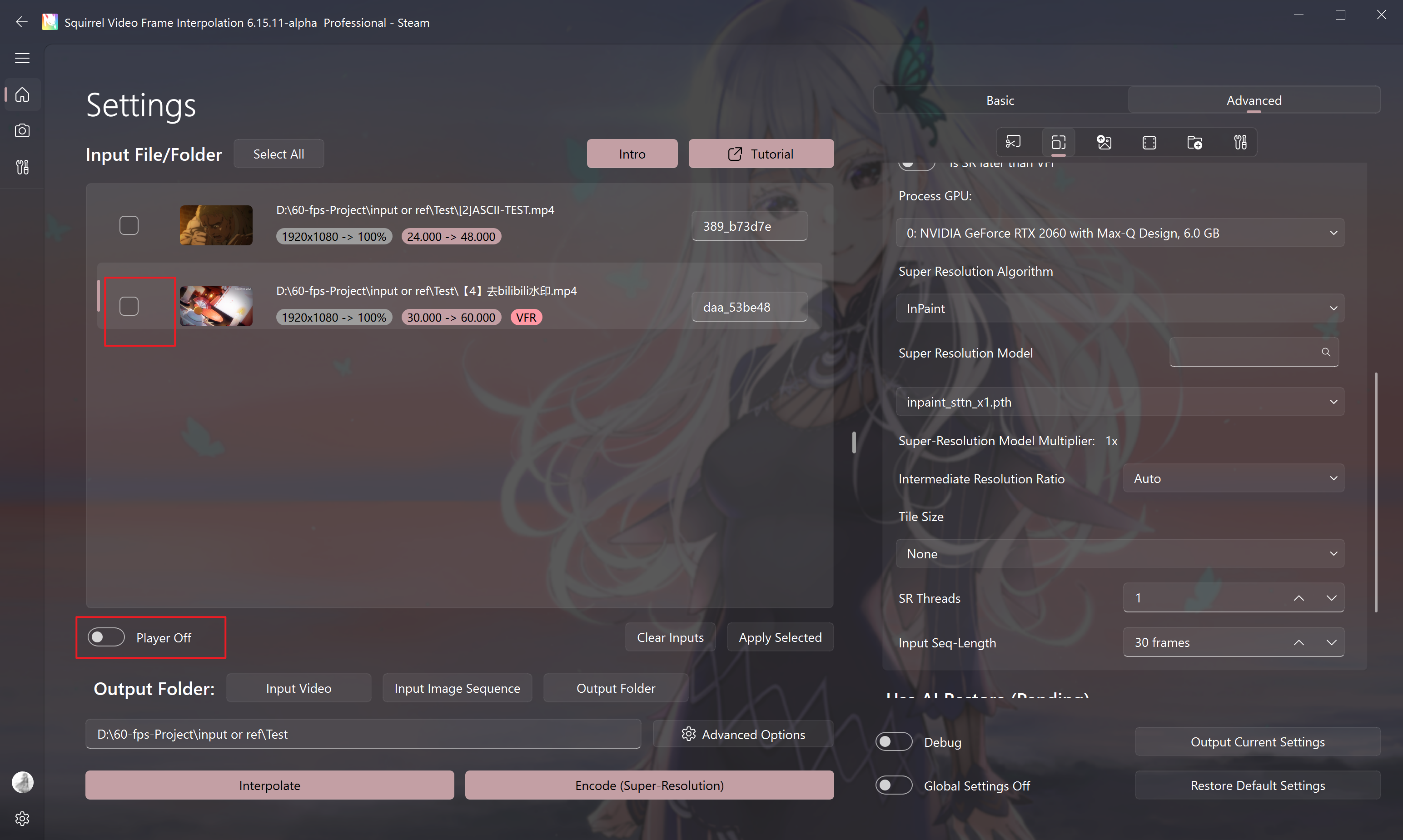
- Enable the mask function
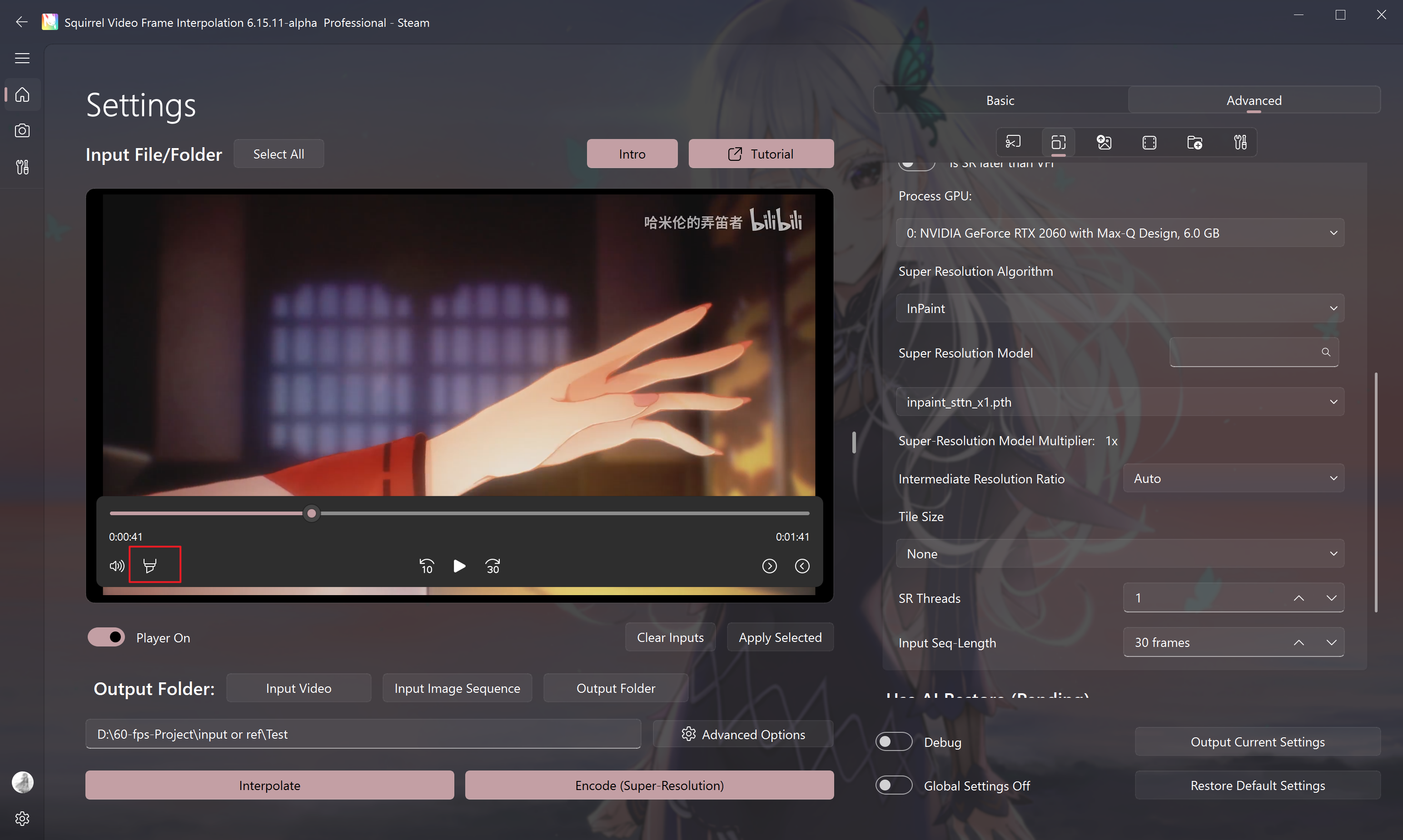
- Draw the mask and save it
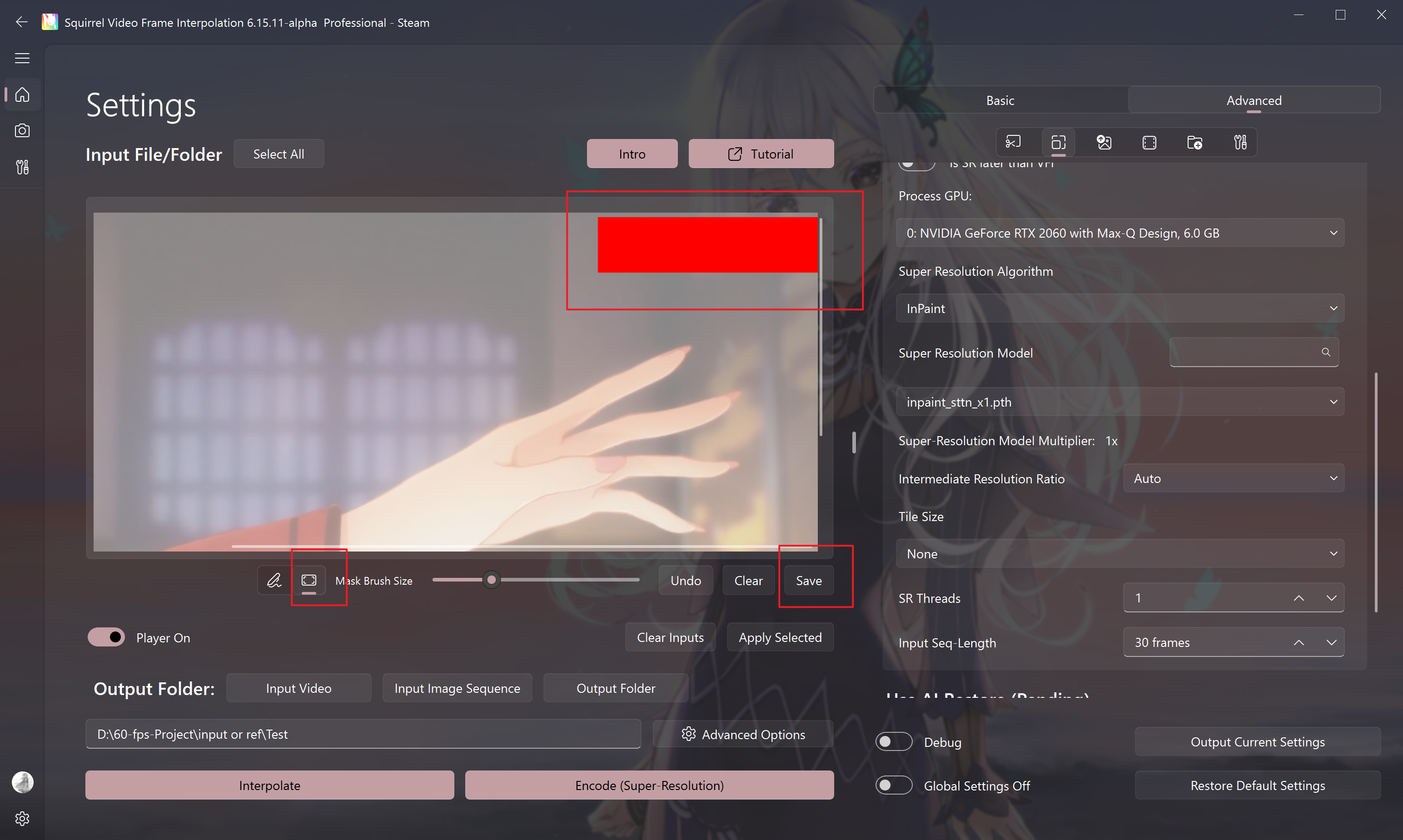
This model will automatically identify and remove static watermarks in each mask area. Please make sure there is enough dynamic change content in the mask area, otherwise it cannot be automatically identified.
Warning
This model has poor performance in identifying and removing watermarks on solid background/static content.
- Click Encode to start removing watermarks

